پیام سپاهان - گجت نیوز / هوش مصنوعی DiffusionGemma گوگل با بهرهگیری از رویکرد دیفیوژن، تولید متن را تا چهار برابر سریعتر از مدلهای معمول انجام میدهد و انقلابی در پردازش زبان طبیعی ایجاد میکند.
شرکت گوگل بهتازگی مدل هوش مصنوعی تجربی و متنباز DiffusionGemma را معرفی کرده که با قابلیت تولید متن موازی، پاسخی به نیاز رو به رشد سرعت در کاربردهای هوش مصنوعی میدهد.
این مدل که بر پایه خانواده قدرتمند Gemma 4 و تحقیقات Gemini Diffusion گوگل دیپمایند ساخته شده، ۲۶ میلیارد پارامتر دارد و با تمرکز بر راندمان هوش مصنوعی به ازای هر پارامتر، رویکرد متفاوتی در تولید محتوا در پیش گرفته است.
هوش مصنوعی DiffusionGemma: انقلابی در تولید متن
برخلاف مدلهای زبان بزرگ (LLM) خودرگرسیو که متن را توکن به توکن و بهصورت دنبالهای تولید میکنند، این هوش مصنوعی گوگل کل بلوکهای متنی را بهطور همزمان تولید و اصلاح میکند. این مدل با شروع از توکنهای جایگزین تصادفی، بهتدریج آنها را از طریق چندین مرحله کاهش نویز بهبود میبخشد تا متن به خروجی نهایی برسد؛ فرایندی مشابه آنچه در تولیدکنندگان تصویر مبتنی بر دیفیوژن دیده میشود.
بازار

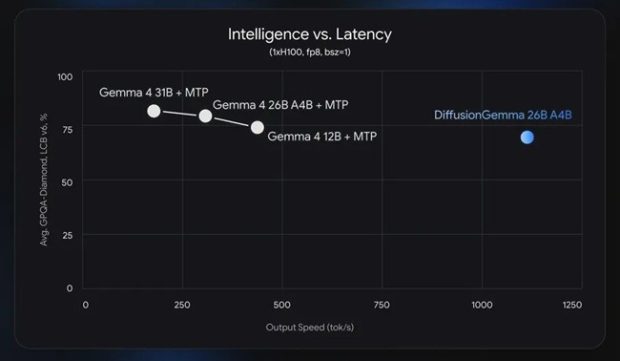
مهندسان گوگل میگویند این مدل میتواند تولید متن را تا چهار برابر سریعتر روی پردازندههای گرافیکی (GPU) انجام دهد. این ویژگی آن را برای محققان و توسعهدهندگان در کارهای محلی با اهمیت بالا از نظر سرعت، مانند ویرایش درونخطی و تکرار سریع، بسیار مناسب میکند.
عملکرد و کاربردها در دنیای واقعی
با توجه به معماری MoE، مدل هوش مصنوعی دیفیوژن جما در زمان استنتاج تنها ۳٫۸ میلیارد پارامتر را فعال میکند و در صورت کوانتیزه شدن، میتواند در حدود ۱۸ گیگابایت حافظه VRAM جای گیرد که اجرای آن را روی پردازندههای گرافیکی قدرتمند مصرفکننده امکانپذیر میسازد. گوگل و انویدیا اعلام کردهاند که DiffusionGemma بار کاری تولید متن را از گلوگاه پهنای باند حافظه به بار محاسباتی فشرده تغییر میدهد و از تواناییهای پردازندههای گرافیکی مدرن و هستههای Tensor Core انویدیا بهتر استفاده میکند. این شرکتها عملکرد قابل توجهی از جمله تولید بیش از ۱٬۰۰۰ توکن در ثانیه روی یک پردازنده NVIDIA H100 و بیش از ۷۰۰ توکن در ثانیه روی NVIDIA GeForce RTX 5090 را برای این مدل گزارش کردهاند.

قابلیت توجه دوطرفه دیفیوژن جما آن را برای کارهایی مانند ویرایش درونخطی، تکمیل کد، نمودارهای ریاضی و توالیهای آمینواسیدها بسیار مناسب میسازد. این مدل میتواند در چتهای تعاملی، دستیارهای هوش مصنوعی محلی، دستیارهای روی دستگاه و سایر برنامههای کاربردی حساس به تأخیر مورد استفاده قرار گیرد.
البته گوگل خاطرنشان میکند که کیفیت کلی خروجی DiffusionGemma در حال حاضر پایینتر از مدلهای استاندارد Gemma 4 است و برای بالاترین کیفیت در خروجیهای تولیدی، Gemma 4 همچنان توصیه میشود.
بهینهسازی و اکوسیستم توسعهدهندگان
شرکت انویدیا DiffusionGemma را در سراسر اکوسیستم سختافزاری خود، از جمله پردازندههای گرافیکی GeForce RTX و ایستگاههای کاری RTX PRO، بهینهسازی کرده است. این همکاری نزدیک بین گوگل و انویدیا، پشتیبانی از استقرار کوانتیزه شده روی پردازندههای GeForce RTX 4090 و RTX 5090 و همچنین سیستمهای Hopper و Blackwell با استفاده از هستههای پیشرفته NVFP4 را فراهم میآورد.
دیفیوژن جما بهعنوان مدل متنباز آزمایشی تحت مجوز Apache 2.0 در دسترس قرار گرفته و از زمان عرضه، از فریمورکها و ابزارهای توسعهدهنده متعددی مانند Hugging Face Transformers و vLLM پشتیبانی میکند تا توسعهدهندگان بتوانند بهراحتی از قابلیتهای آن بهرهمند شوند.